![]()
Data Science Techniques and Applications (DSTA) 2019-20
Evaluating Classification performance
Slides and codes courtesy of Andreas C. Müller, NYU
Supervised Binary Classification
Istance:
a collection X
its classification y (assume a classification sys. {0,1} or {-1, +1})
Solution: a classifier function (here called model)
Measure: misclassification wrt. y

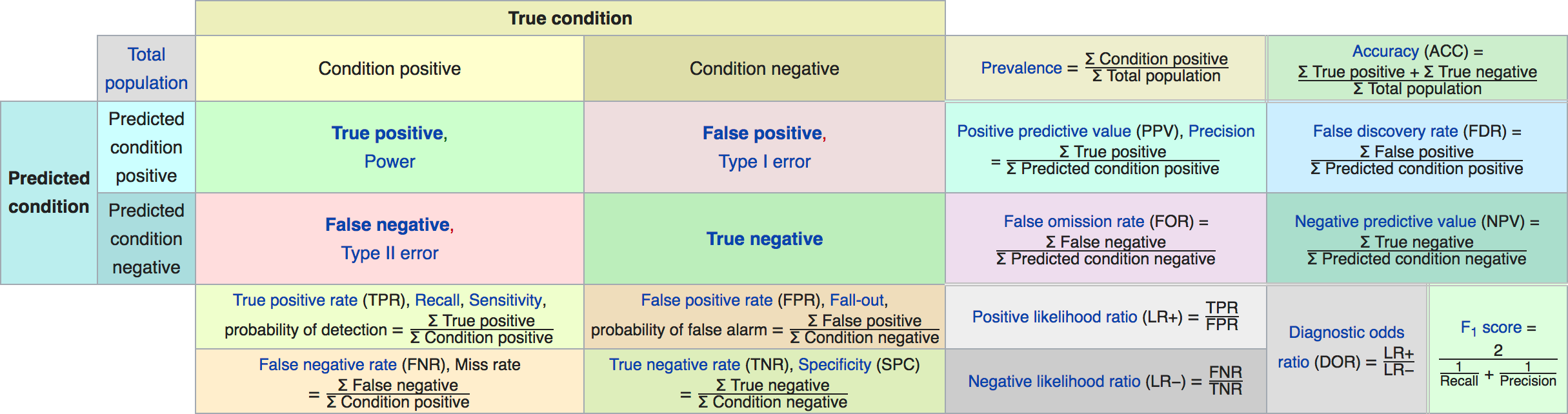
Confusion matrix

Example: evaluate the LogisticRegression classifer
from sklearn.datasets import load_breast_cancerfrom sklearn.linear_model import LogisticRegressiondata = load_breast_cancer()X_train, X_test, y_train, y_test = train_test_split( data.data, data.target, stratify=data.target, random_state=0)lr = LogisticRegression().fit(X_train, y_train)y_pred = lr.predict(X_test)from sklearn.metrics import confusion_matrixprint(confusion_matrix(y_test, y_pred))print(lr.score(X_test, y_test))
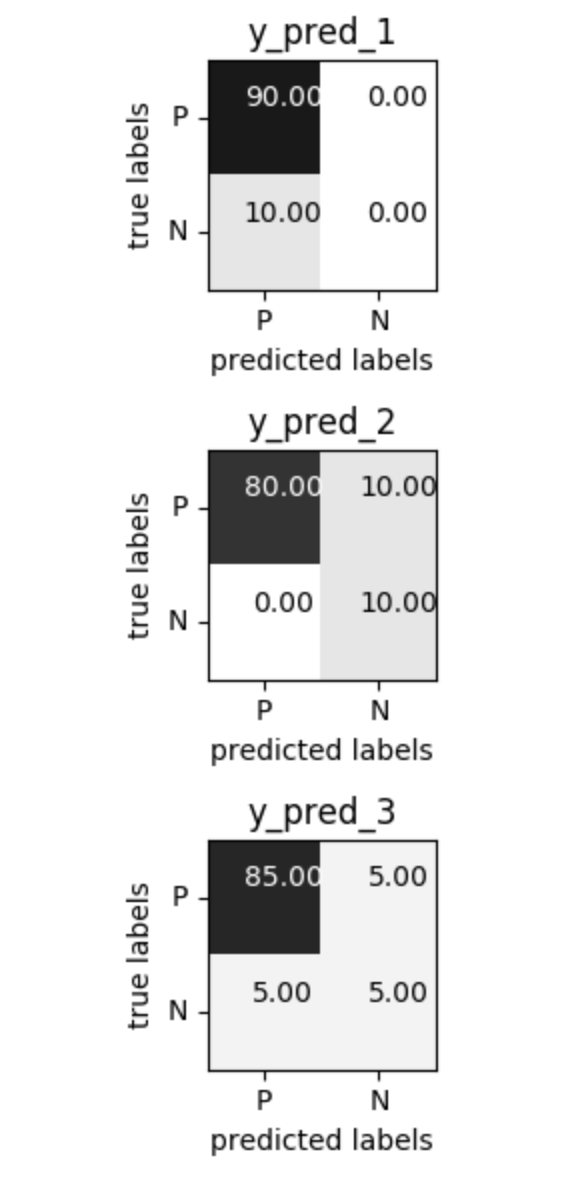
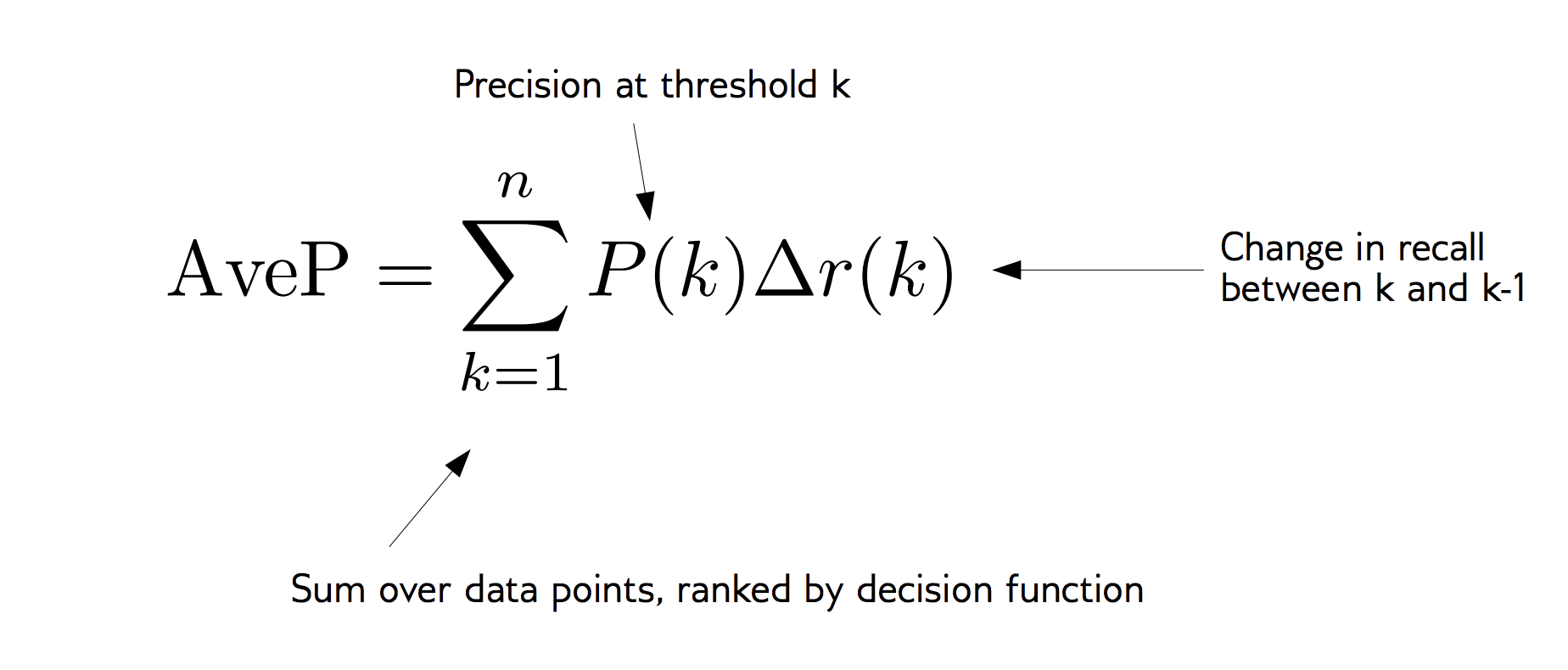
Problems with Accuracy
Data with 90% positives:
from sklearn.metrics import accuracy_scorefor y_pred in [y_pred_1, y_pred_2, y_pred_3]: print(accuracy_score(y_true, y_pred))0.90.90.9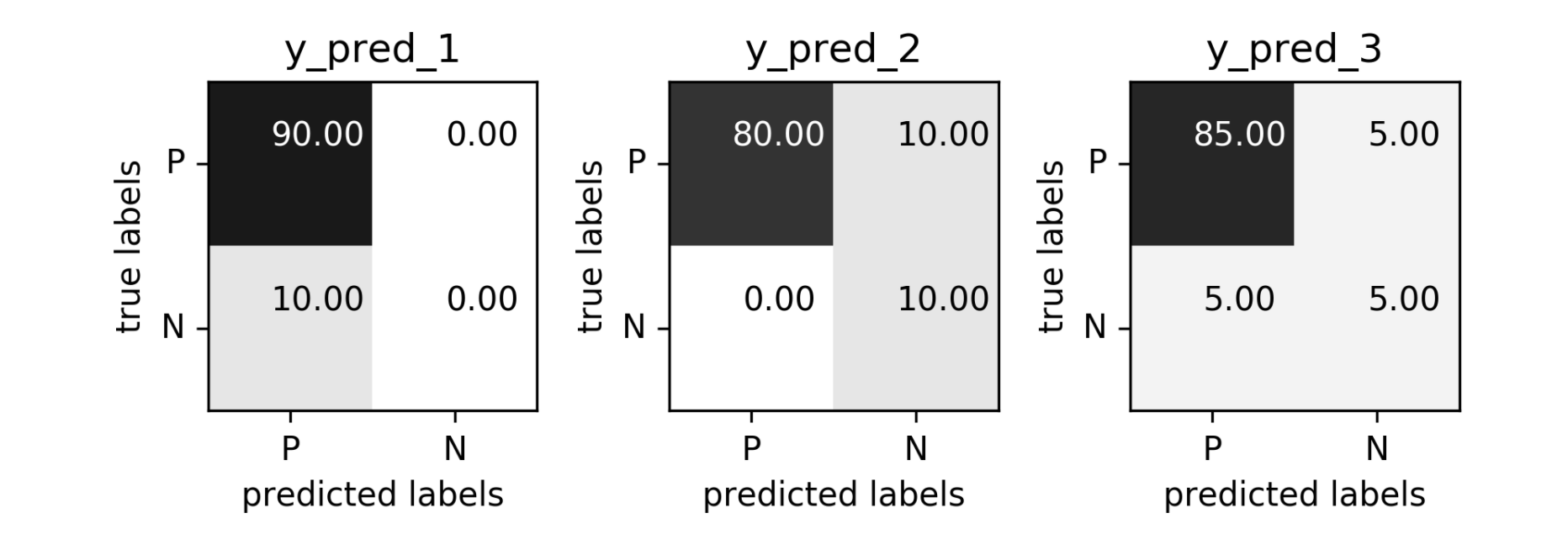


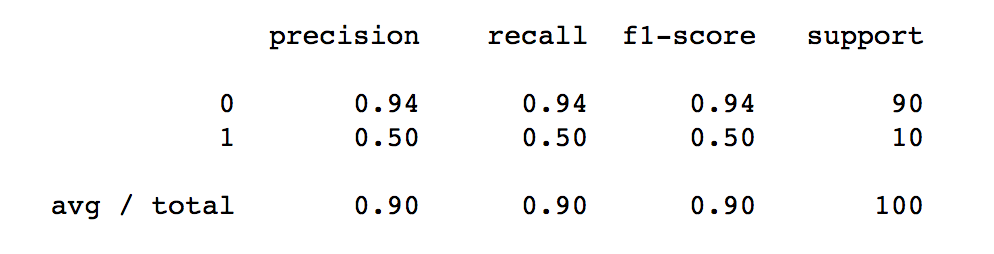
The Precision-Recall curve of an SVC classifier
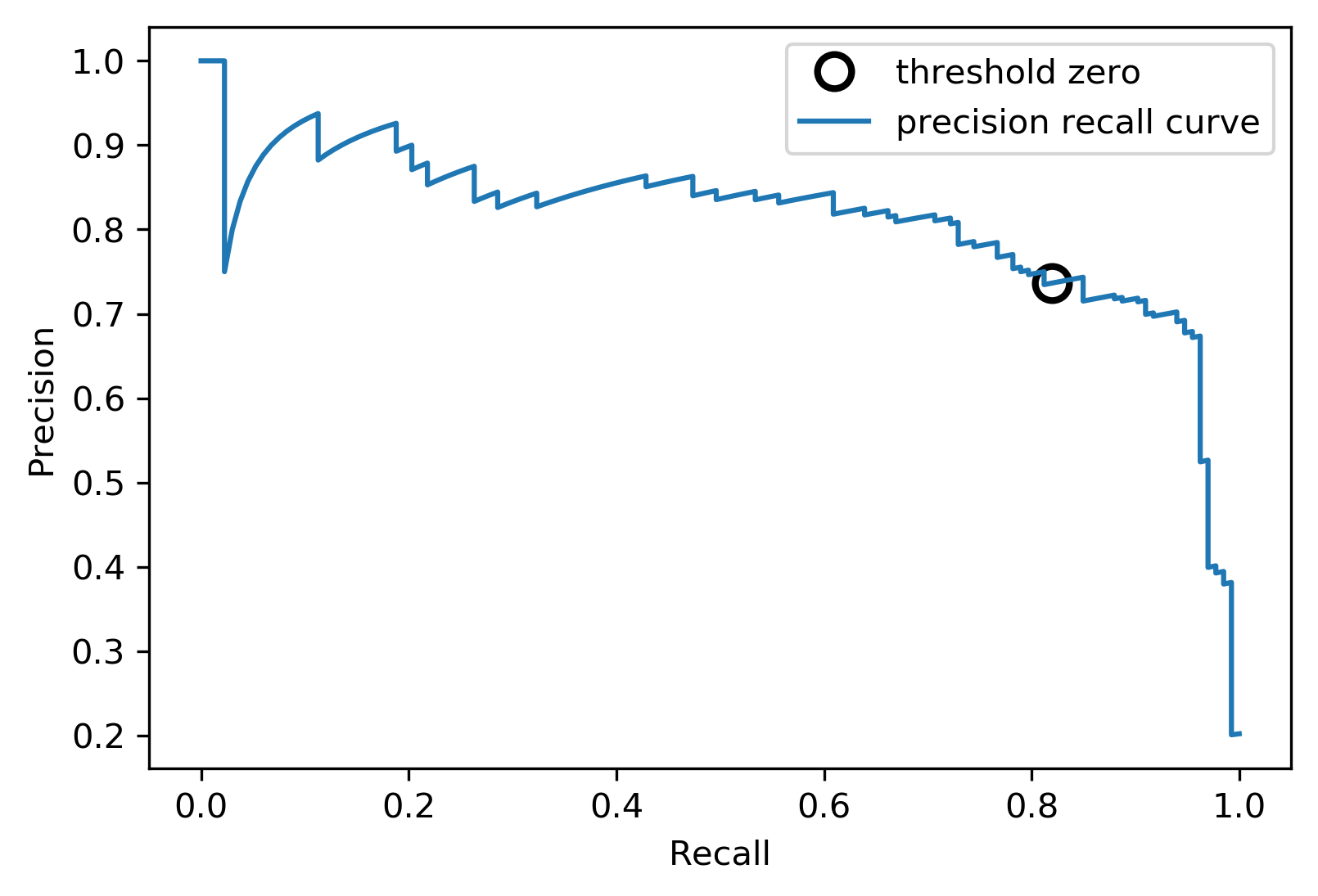
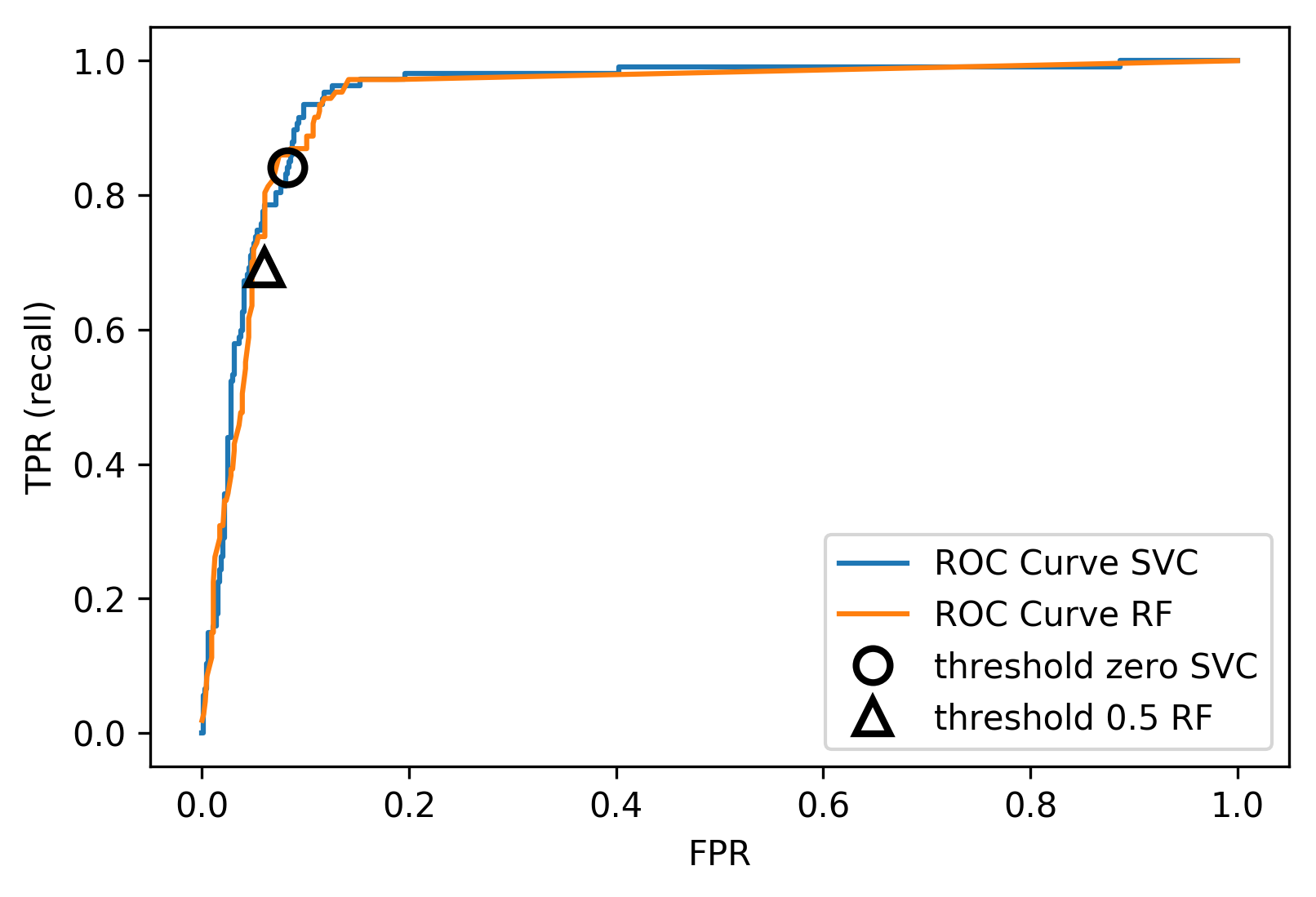
Comparing RF and SVC
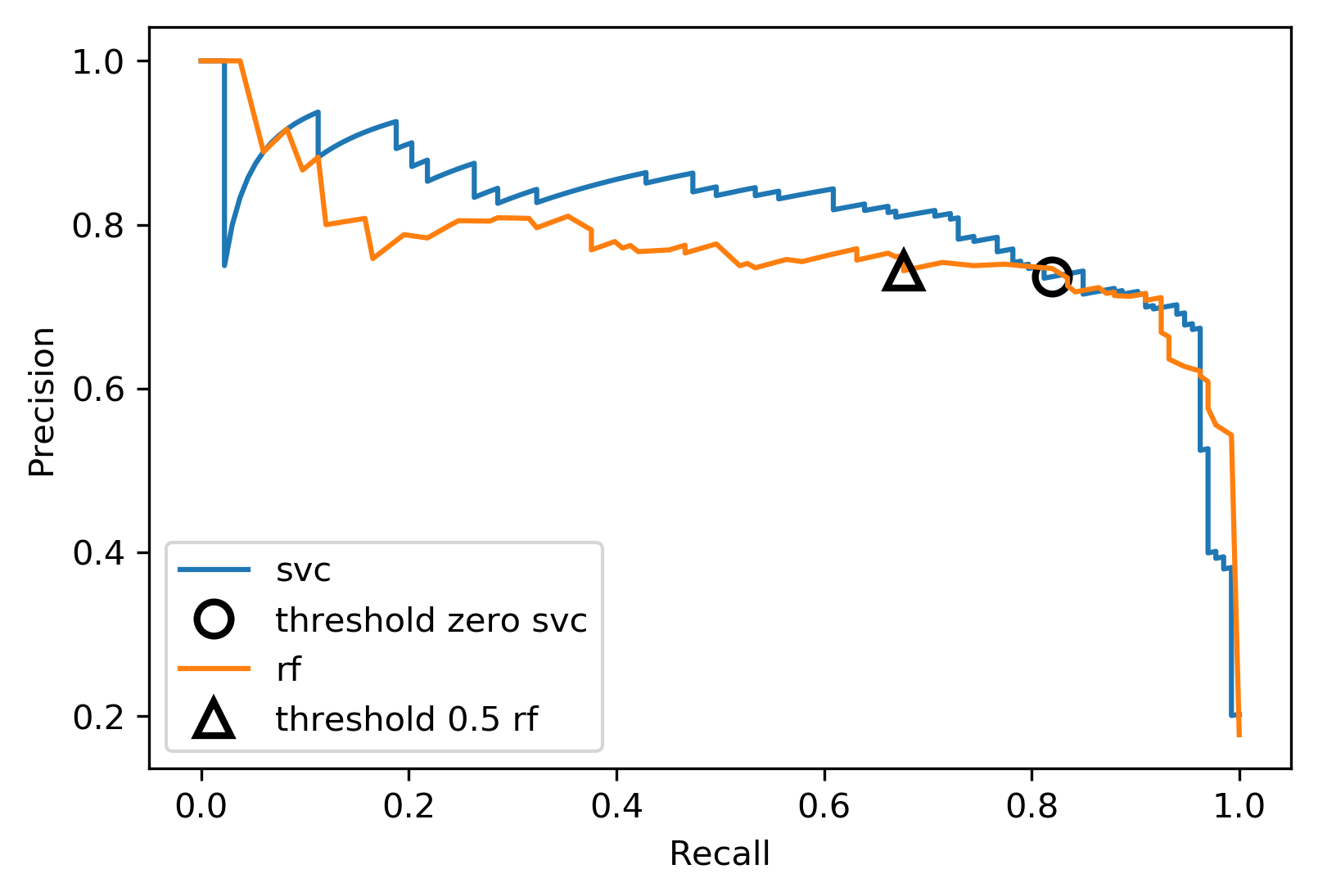
Alternative: Average Precision
The ROC Curve